Dopo qualche tempo dall’esperienza con lo Scunthorpe finita male, così come il PC su cui ci stavo giocando, nei ritagli di tempo ho cominciato una nuova stagione con un’altra squadra di 3rd Division inglese il Lincoln City. Questa volta ho deciso di riportare in un excel una serie di informazioni che possano venire utili durante il gioco anche per solo temi statistici. Di volta in volta esporrò alcuni di questi fogli excel per spiegare meglio a cosa servono e perchè li utilizzo.
La Squadra
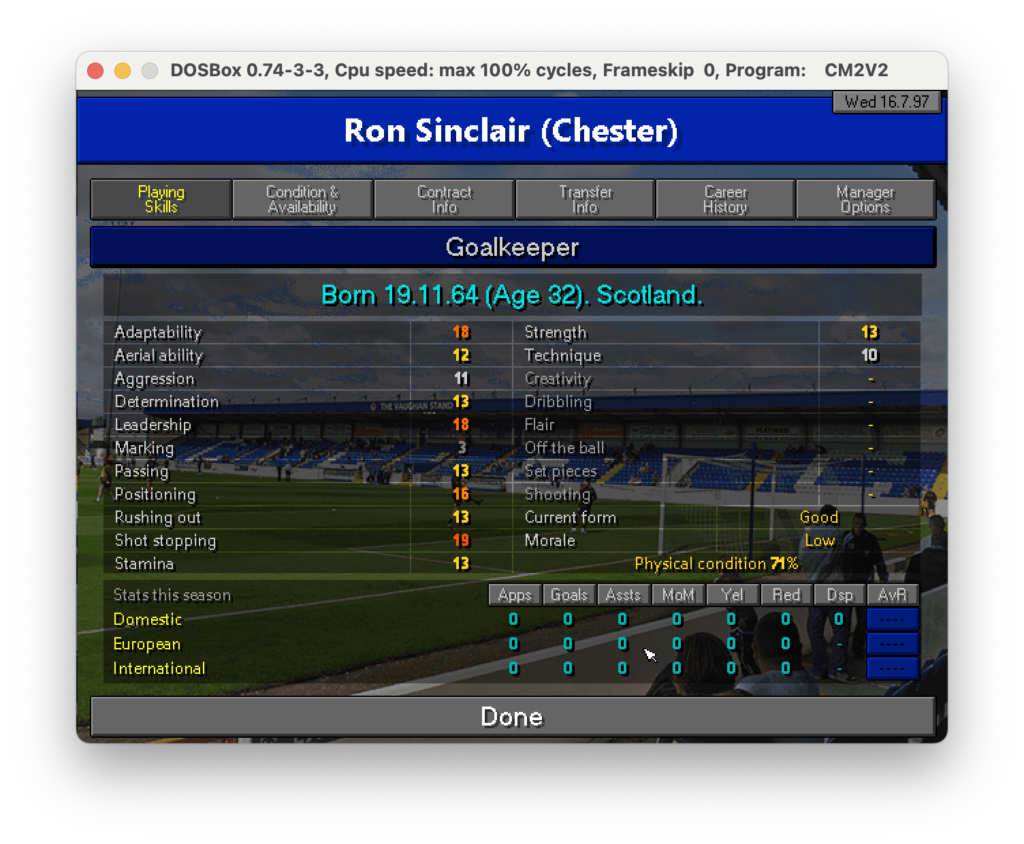
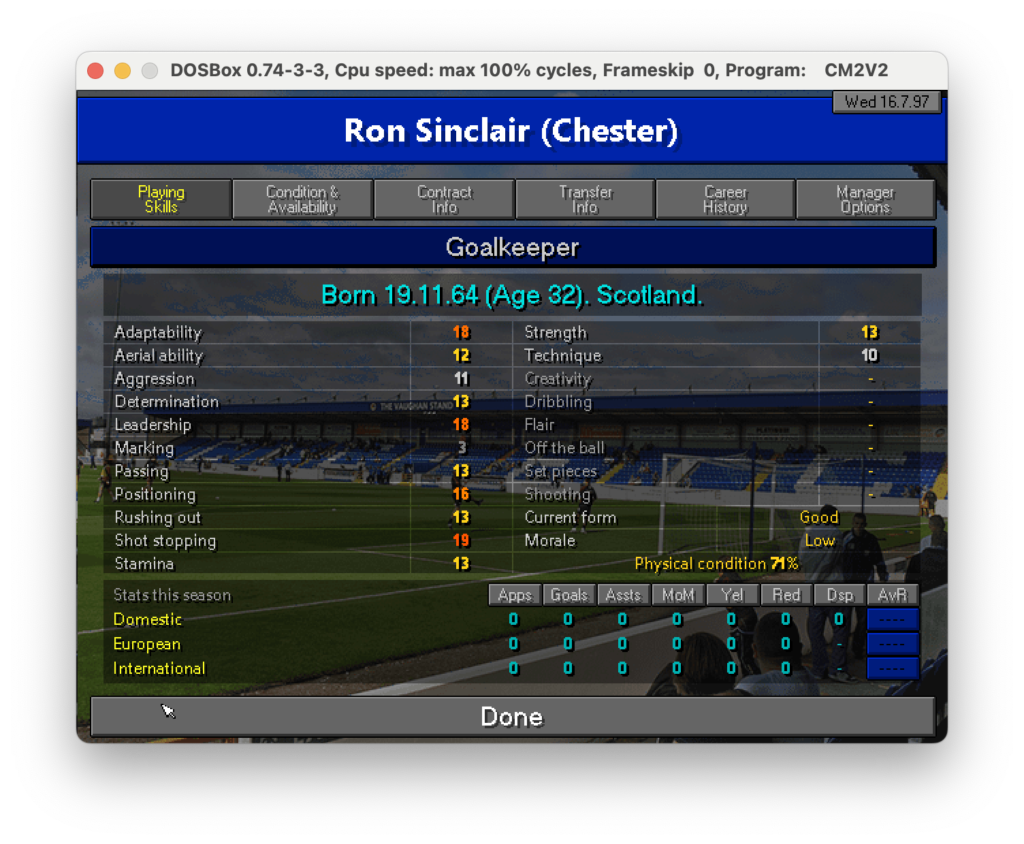
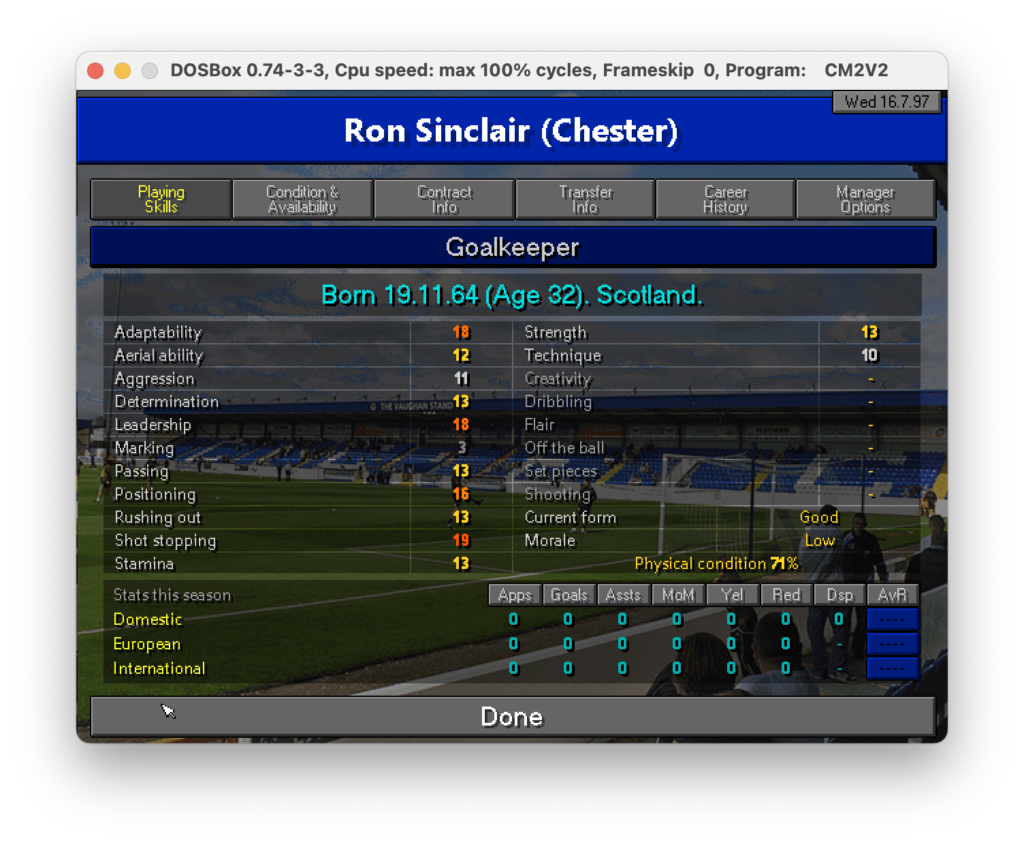
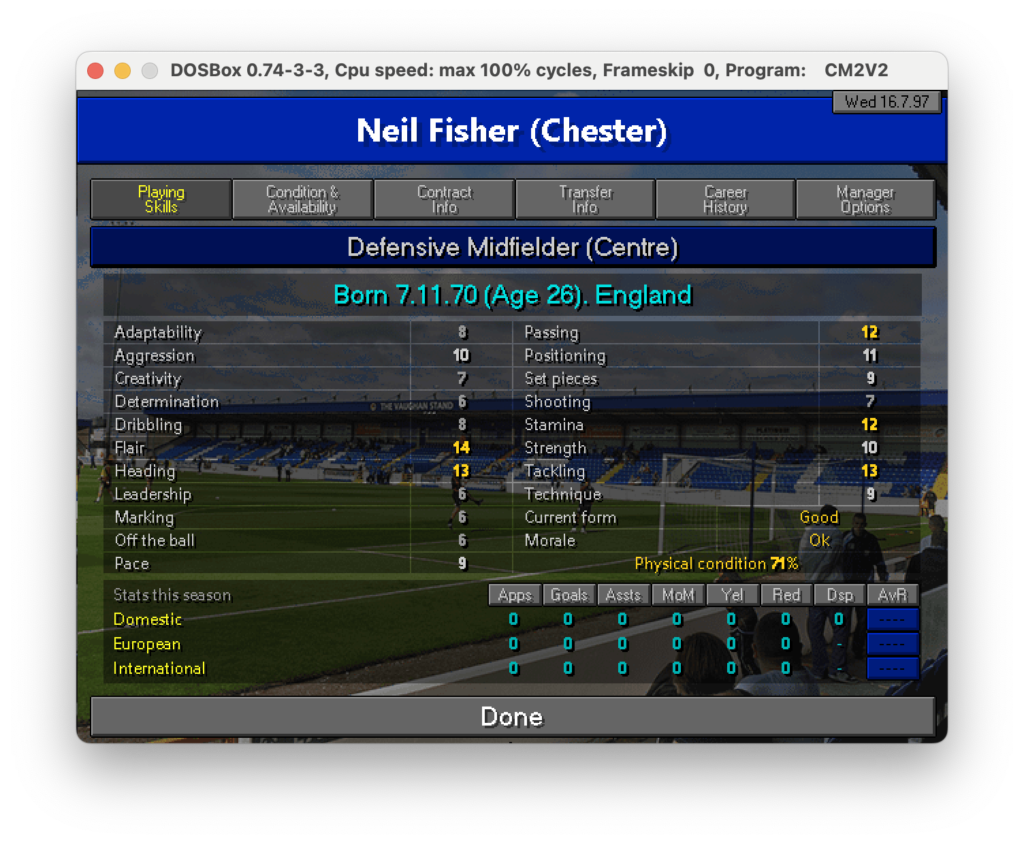
Nel foglio “PL Skills” ho riportato per tutti i giocatori le informazioni princiali quali ruolo, età, nazionalità e skills.
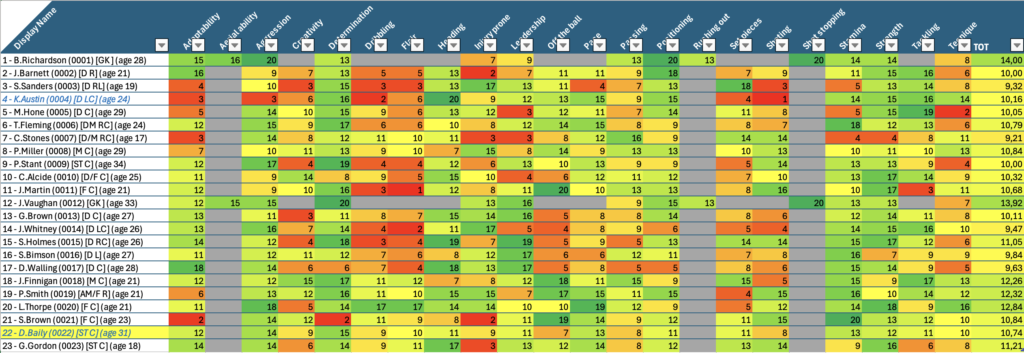
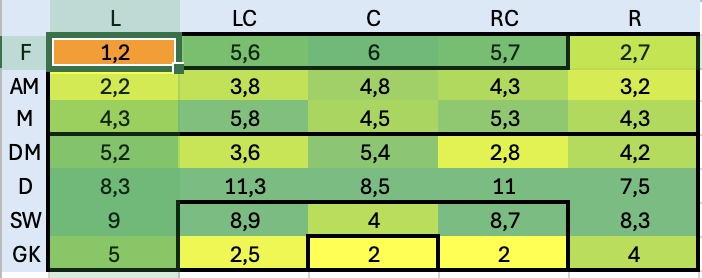
Questa tabella è usata come tabella principale su cui fare lookup per ogni giocatore in tutte le tabelle del foglio excel. In questo modo, anche con l’aiuto del colore (basso -> rosso, alto -> verde) dà già un’idea di massima di come siano distributite le skills ei giocatori. Sfruttando la potenza di PowerQuery mi sono costruito poi una roadmap che in base alle posizioni in campo va a distribuire le skills per dare un’idea di quanto siano coperte le varie parti del campo. il risultato è il seguente:
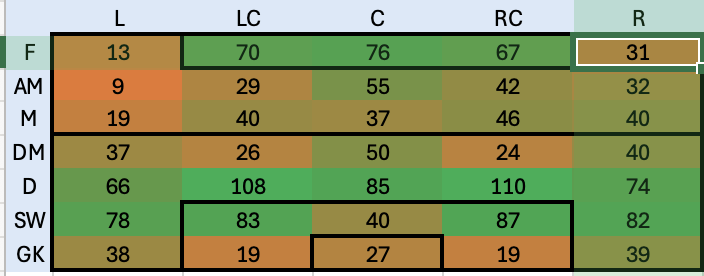
E’ evidente com la parte di granlunga più debole sia la fascia sinistra ed anche la linea mediana non sembra avere un grosso ricambio. La parte centra dell’attacco e della difesa invece sembrano molto più coperte, probabilmente troppo. Decido quindi di buttarmi alla ricerca di esterni di sinistra che possano coprire meglio quella parte di campo.
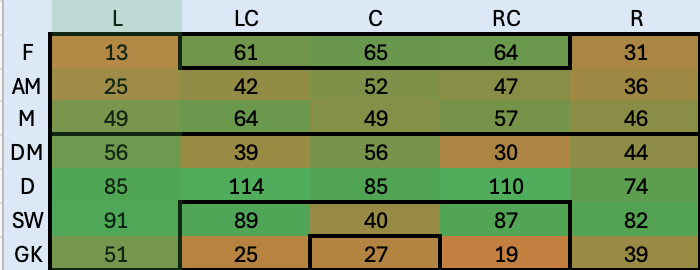
Similmente creo una Hitmap che identifichi la copertura del ruolo in modo da capire anche quelli che sono i ruoli meno coperti, non solo quelli più deboli
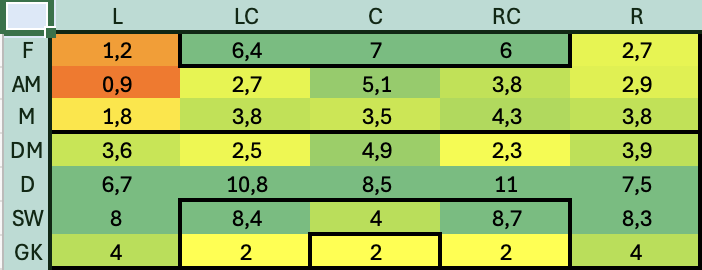
In questo caso l’indicazione è convergente con quella precedente: la fascia sinistra dalla meta campo in su è fortemente scoperta ed è certamente da rinforzare. Diciamo che da questa analisi ci portiamo a casa le seguenti informazioni:
- Nei ruoli d’attacco abbiamo una grande abbondanza: in media abbiamo 6 contendenti per 2 posti (assumo di non giocare con 3 attaccanti)
- La fascia sinistra richiede un bel boost
- Nei ruoli di difesa, in particolare quelli centrali c’è una grande abbondanza con 10 contendenti per, probabilmente, 2 massimo 3 ruoli.
Precampionato e calcio mercato
Partendo dalle considerazioni di cui sopra organizzo 3 amichevoli precampionato per cominciare a vedere un po’ la squadra e capire con che modulo giocare ma soprattutto quali giocatori preferire.

La prima gara è con una squadra del nostro campionato in trasferta. Per la formazione mi faccio guidare da come è composta la rosa e schiero un 3-5-2 che però non mi convince, perdiamo 2-1 senza molte luci. Al termine di questa gara mi viene fatta un’offerta molto interessante per Baily attaccante 31enne in scadenza di contratto a fine anno. Accetto: in attacco siamo molto coperti ed un modo anche per fare cassa. Per la seconda gara, sempre contro una squadra della nostra division, schiero un classico 4-4-2 adattando un centrale sulla sinistra non avendo giocatori di ruolo: va alla grande vinciamo 4-1 dominando sostanzialmente la gara. A questo punto bollo il 4-4-2 come modulo migliore o cmq più affidabile al momento. In questa settimana riesco a mettere anche a segno un paio di acquisti per la fascia sinistra:
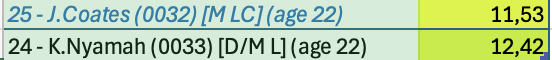
Dopo questi cambi nell’organico le nuove hitmap sono le seguenti:
Nell’ultima gara del precampionato affrontiamo in casa un squadra di Second Division, finisce 0-0 non molte occasioni. Nyamah ha giocato solo il primo tempo senza incidere particolarmente.
Non resta dunque che partire con la stagione che comincia con un trasferta per un mese d’agosto massacrante in cui si giocherà ogni 3-4 gg.