Qualche giorno fa in questo post [1] parlavo dei temi relativi all’AI e le sue differenze con la pura automazione. Come esempio pratico vorrei provare ad acquisire in automatico i dati provenienti da alcune immagini e convogliare queste informazioni in un excel. Dovete sapere che io sono un grande amante dei giochi degli anni ottanta e novanta. E voi direte che centra questo? Uno dei giochi sul quale ho perso letteralmente le notti quando ero poco più che un teenager era Championship Manager (Scudetto nell’edizione italiana). E’ stato il primo gioco a fornire una simulazione di ottimo livello del manager calcistico. Sono passati gli anni, sarà l’età avanzata, sarà del sano romanticismo, ma ancora questo gioco riesce a toccare corde cui i giochi strafighi di oggi difficilmente riescono a sfiorare. Se non lo conoscete vi invito a fare un giro su questo sito [2] dove potete addirittura scaricare il gioco (nella versione 97/98) e con dosbox [3] un simulatore di DOS potete persino giocarci. Ebbene una delle cose che ho sempre desiderato fare è avere uno scarico dei dati di giocatori e partite per poterli incrociare avere delle statistiche da cui possibilmente evincere trends ed informazioni utili a schierare le formazioni migliori.
Una schermata di esempio è quella delle skills di un singolo calciatore in cui ci sono info anagrafiche e capacità tecniche
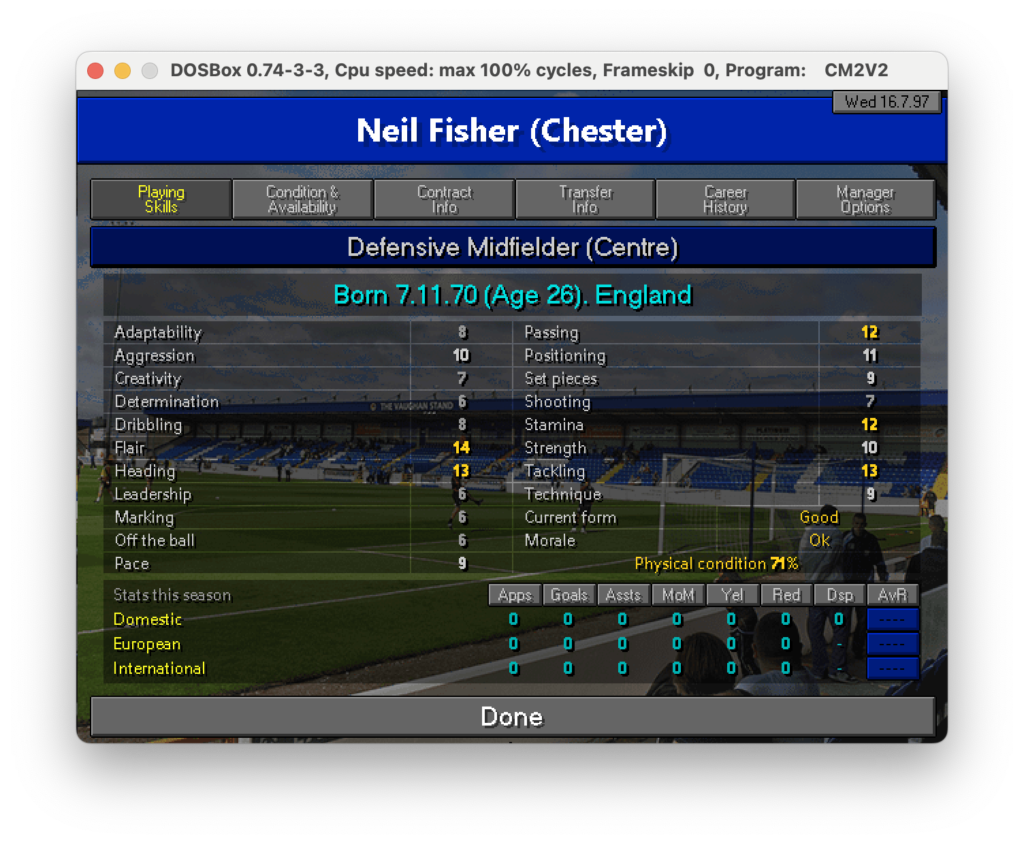
Nella fattispecie mi piacerebbe quindi avere in un unico excel le skills per colonna e i giocatori per riga magari indicando anche la data in cui questi dati sono stati raccolti con l’idea di poter monitorare un giocatore anche in giorni diversi nel caso le sue skills migliorino o peggiorino. Detto questo non ho la minima idea di come procedere, quindi chiedo a ChatGPT se mi può dare una mano:

Chiedo scusa per l’inglese maccheronico, ma penso si capisca abbastanza bene. Ed ecco la risposta:

Bene, diciamo che già la lista delle attività pone sul tavolo alcuni strumenti come Python, OpenCV… In più mi porta cnhe un esempio di codice Python da utilizzare:
import os
import cv2
import pytesseract
import csv
from datetime import datetime
# Function to categorize screenshots based on format
def categorize_screenshots(screenshot_folder):
# Implement your logic to categorize screenshots
pass
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(img)
# Extract relevant information from the data
# Rename the file using extracted data and current date
new_filename = f"{extracted_data}_{datetime.now().strftime('%Y-%m-%d')}.png"
os.rename(img_path, os.path.join(screenshot_folder, new_filename))
# Function to fill CSV files with data from screenshots
def fill_csv_files(screenshot_folder, csv_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
extracted_data = pytesseract.image_to_string(img)
# Write extracted data to CSV file
csv_filename = file.replace(".png", ".csv")
with open(os.path.join(csv_folder, csv_filename), "w", newline="") as csvfile:
csv_writer = csv.writer(csvfile)
# Write data to CSV file
csv_writer.writerow(extracted_data.split("\n"))
# Main function to execute the workflow
def main():
# Path to the folder containing screenshots
screenshot_folder = "path/to/screenshots"
# Path to the folder where CSV files will be stored
csv_folder = "path/to/csv_files"
# Categorize screenshots
categorize_screenshots(screenshot_folder)
# Extract data from screenshots and rename files
extract_data_and_rename(screenshot_folder)
# Fill CSV files with data from screenshots
fill_csv_files(screenshot_folder, csv_folder)
if __name__ == "__main__":
main()
Fantastico: non avevo idea da dove cominicare e ChatGPT mi ha dato delle indicazioni preziose per cominiciare ad approfondire i temi.
Python
Non conosco questo linguaggio se non per sentito dire: non ho mai scritto mezza riga di codice, ma mi sembra di poter dire, dall’esempio che riporta ChatGPT, non sia poi così complesso. Leggendo su Wikipedia [4] tra l’altro scopro che deve il nome ai Monthy Python, già questa la dice lunga. Installarlo non è complesso basta seguire gli step indicati nelle varie guide online (tipo questa [5]). Anzitutto verifico che non sia già presente con questo comando a terminale:
python --versionNel mio caso il risultato è quello che vedete (io ho installato la versione 3)

Nel caso non lo abbiate installato potete seguire la guida utilizzando brew
brew install pythonOra che Python è finalmente installato possiamo aprire Visual Studio code e utilizzando il codice che ChatGPT ci ha fornito creiamo un file .py di test da eseguire.
Nel prossimo post vedremo le librerie da utilizzare in Python così come ce le ha suggerite ChatGPT.
[1] https://www.beren.it/2024/02/08/automazione-o-intelligenza-artificale/
[2] https://www.fmscout.com/a-cm9798-v2-project.html