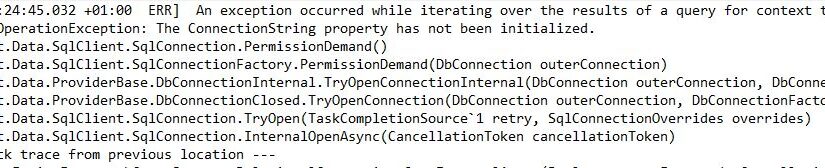
Quando si lavora su una soluzione è vitale che si abbia la possibilità di differenziare delle configurazioni in base all’ambiente di destinazione “target” della soluzione. L’esempio più semplice è quello delle stringhe di connessione a DB: se si hanno ambienti diversi normalmente serviranno delle stringhe differenti in base al DB. In generale per i progetti asp.net core (e non solo) è possibile gestire tanti settings quanti sono gli ambienti di rilascio, però non è così banale trovare un modo per rendere dinamica questa modalità. Ho travato infatti molta documentazione sul come giocare con le variabili di ambiente [1] che però, nell’ambiente target (una soluzione cloud), non mi è possibile toccare. Dopo varie ore a cercare in rete qualcosa di sensato sono approdato a questa soluzione che vi spiego che in parte trovate anche in questo video.
Definizione di ambienti di rilascio: per prima cosa definiamo quali ambienti deve contemplare la mia soluzione per capire quanti varianti di file di configurazione servono. Nel mio caso sono 4:
- Development: la configurazione che utilizzo in Visual Studio quando sviluppo e debuggo
- Stage: la configurazione che utilizzo per testare l’applicazione sul’ISS locale della macchina di sviluppo
- Sandbox: l’ambiente di preproduzione in cloud
- Live: l’ambiente di produzione reale
Per ognuno di questi ambienti mi servirà un file di appsettings dedicato formattato nella seguente maniera: appsettings.{env}.json. Per farlo basta copiare il file appsettings già presente nella soluzione e rinominarlo utilizzando i quattro nomi sopra. Tenete sempre in conto che il primo file ad essere letto è appsettings (quello generico) che poi verrà sovrascritto da quello con il nome dell’ambiente. Questo significa che tutto ciò che chiede di essere specifico per ambiente deve finire in nel file con il nome dell’ambiente stesso.
Caricamento dei settings corretti: in Program.cs carichiamo anzitutto il file appsettings generico all’interno del quale andiamo a creare una configurazione che identifichiamo con Configuration dove scriveremo il target del deploy (uno dei 4 valori sopra). Ed in base a quel valore andiamo a caricare il file dedicato.
var _conf = builder.Configuration.AddJsonFile("appsettings.json", optional: true, false).Build();
string _env = _conf.GetSection("Configuration").Value;
builder.Configuration.AddJsonFile($"appsettings.{_env}.json", optional: true, false);
var app = builder.Build();In questa maniera basterà identificare nel appsettings generico il target del deploy (volendo anche al volo) all’interno della variabile di configurazione Configuration.
Rilasciare solo i files dell’ambiente: per come fatto sopra e sostanzialmente mostrato anche nel video tutti i files appsettings verranno sempre deliverati in tutti gli ambienti e la cosa non mi mpiace molto perchè si presta ad avere errori se non modifico correttamente il Configuration all’interno dell’appsettings generico. Per ovviare a questo problema genero 3 nuove versioni dal configuration manager: Live, Sandbox e Stage. A questo punto apro il file di progetto in edit ed aggiungo la seguente configurazione che rilascia solo il file corretto in base al target che ho scelto.
<Choose>
<When Condition="'$(Configuration)' == 'Live'">
<ItemGroup>
<None Include="appsettings.Live.json" CopyToOutputDirectory="Always" CopyToPublishDirectory="Always" />
<None Include="appsettings.json" CopyToOutputDirectory="Never" CopyToPublishDirectory="Never" />
<Content Remove="appsettings.*.json;appsettings.json" />
</ItemGroup>
</When>
<When Condition="'$(Configuration)' == 'Sandbox'">
<ItemGroup>
<None Include="appsettings.Sandbox.json" CopyToOutputDirectory="Always" CopyToPublishDirectory="Always" />
<None Include="appsettings.json" CopyToOutputDirectory="Never" CopyToPublishDirectory="Never" />
<Content Remove="appsettings.*.json;appsettings.json" />
</ItemGroup>
</When>
<When Condition="'$(Configuration)' == 'Stage'">
<ItemGroup>
<None Include="appsettings.Stage.json" CopyToOutputDirectory="Always" CopyToPublishDirectory="Always" />
<None Include="appsettings.json" CopyToOutputDirectory="Never" CopyToPublishDirectory="Never" />
<Content Remove="appsettings.*.json;appsettings.json" />
</ItemGroup>
</When>
<Otherwise>
<ItemGroup>
<None Include="appsettings.Development.json" CopyToOutputDirectory="Always" CopyToPublishDirectory="Always" />
<None Include="appsettings.json" CopyToOutputDirectory="Never" CopyToPublishDirectory="Never" />
<Content Remove="appsettings.*.json;appsettings.json" />
</ItemGroup>
</Otherwise>
</Choose>In questo modo basterà prima di rilasciare in uno degli ambienti selezionare la tipologia di deploy e verranno solo rilasciati i files di configurazione relativi.
[1] https://learn.microsoft.com/en-us/aspnet/core/fundamentals/configuration/?view=aspnetcore-8.0#evcp