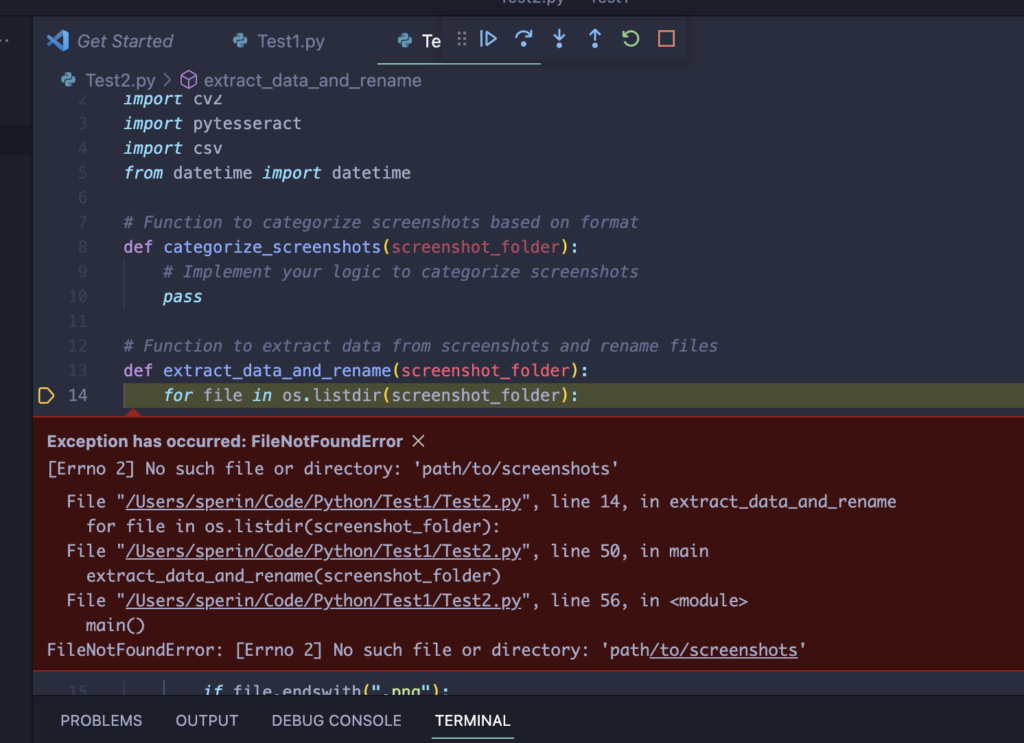
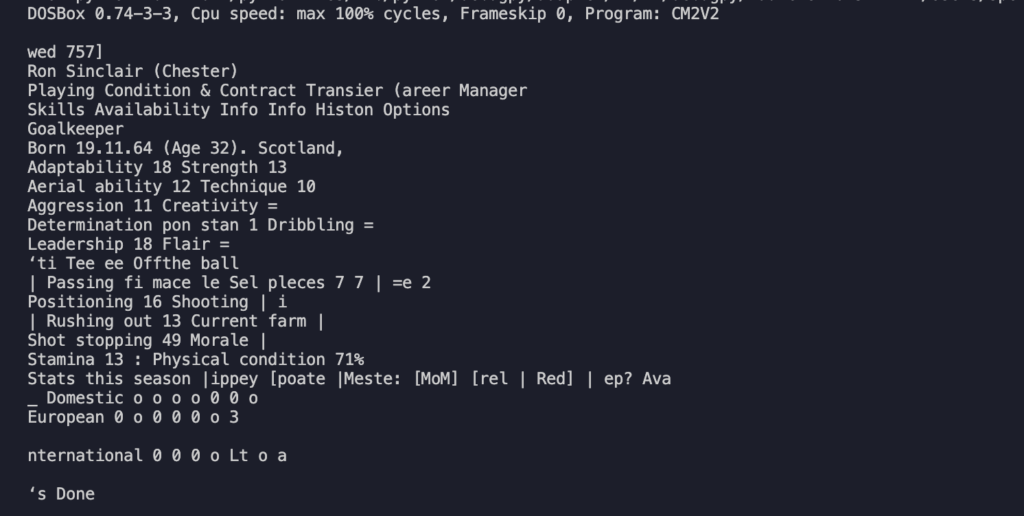
Nello scorso post abbiamo visto come estrarre i testi da una schermata. Purtroppo nel caso analizzato abbiamo molti dati dispersi in vari punti e questo ci ha fornito un estratto difficilmente elaborabile.
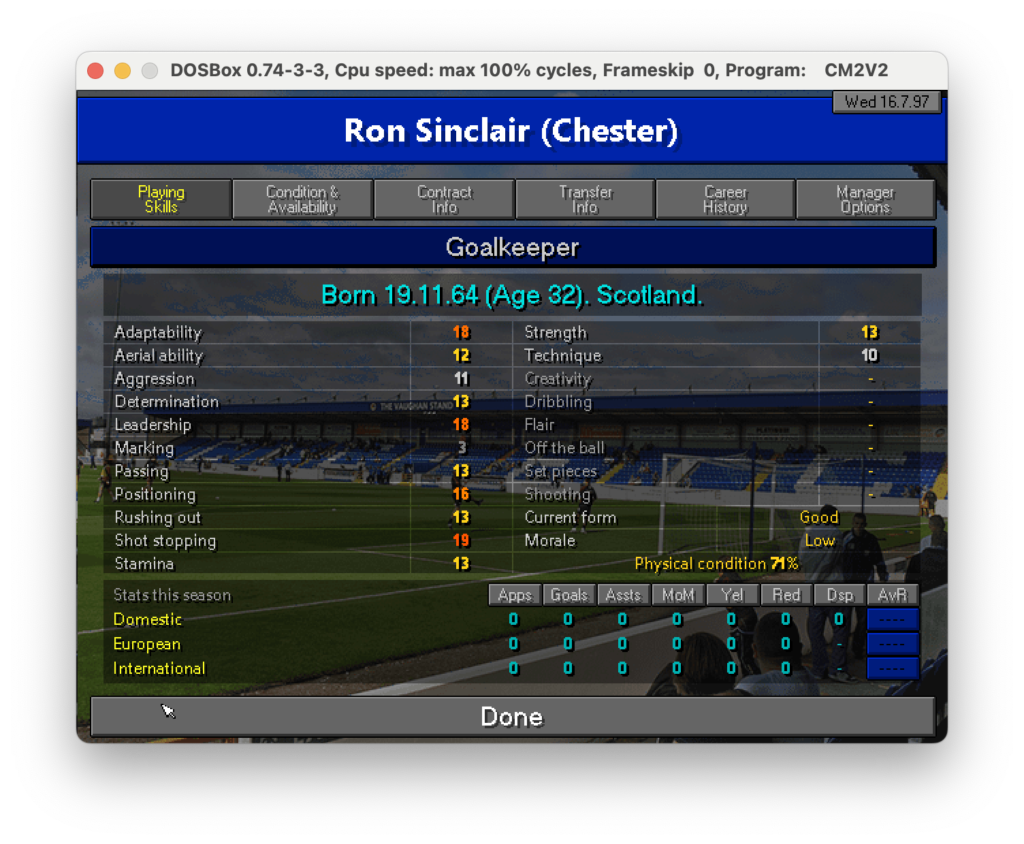
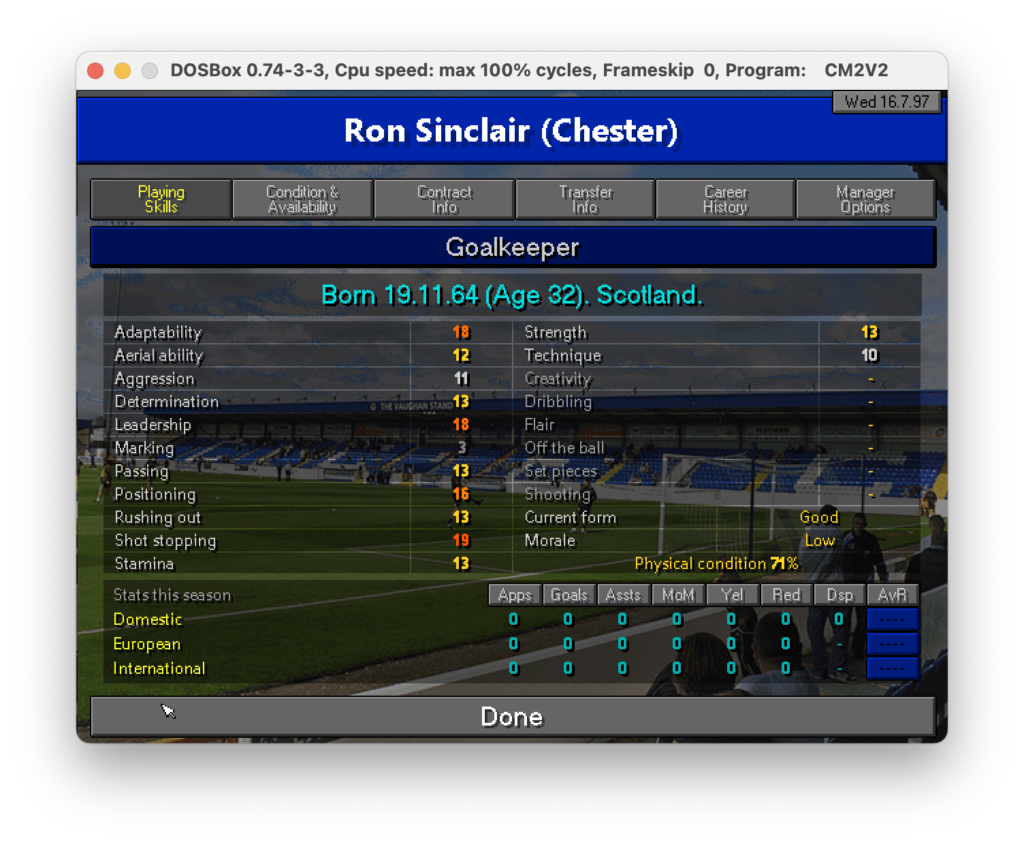
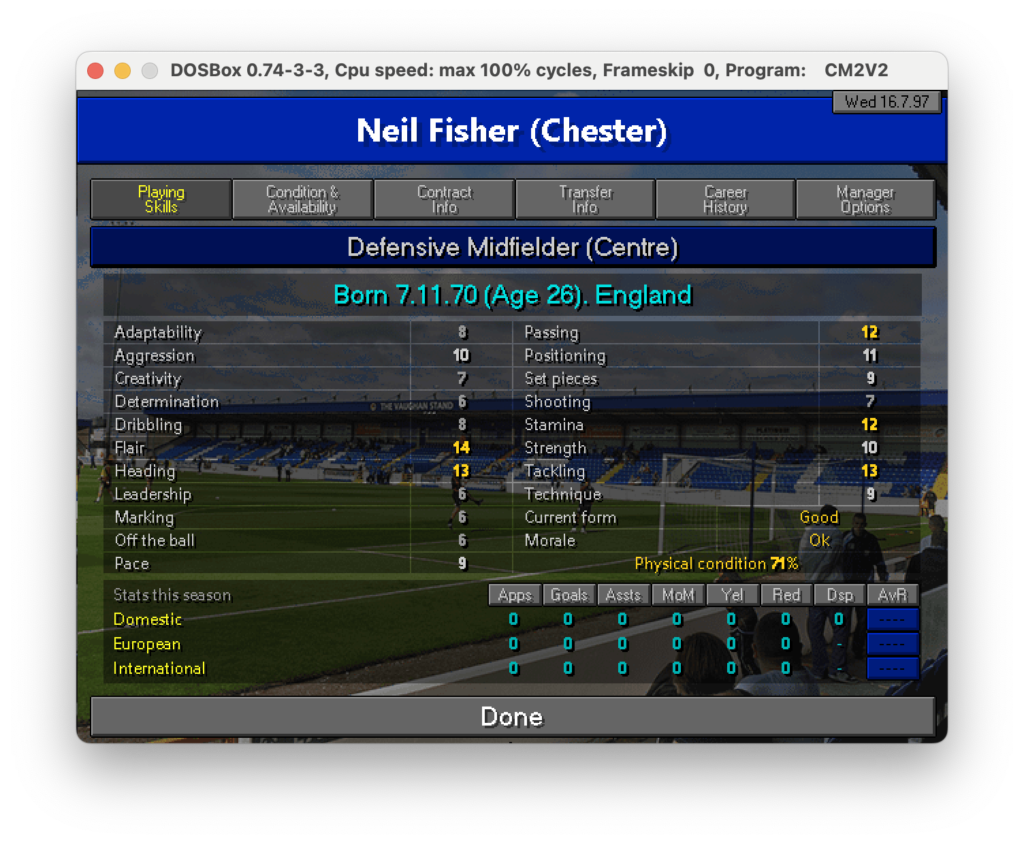
Ciò che gioca a nostro favore in realtà è che il formato del dato è quello per tutte le schermate, ciò che cambierà sarà certamente il nome del calciatore, le info anagrafiche ed i valori delle skills. Fortunatamente la struttura ed il posizionamento sono praticamente identici. In soldoni: sappiamo precisamente dove andare a reperire le informazioni, quindi se ci fosse un modo per restringere il campo potremmo estrarre i dati un po’ alla volta selezionando solo ciò che ci serve.
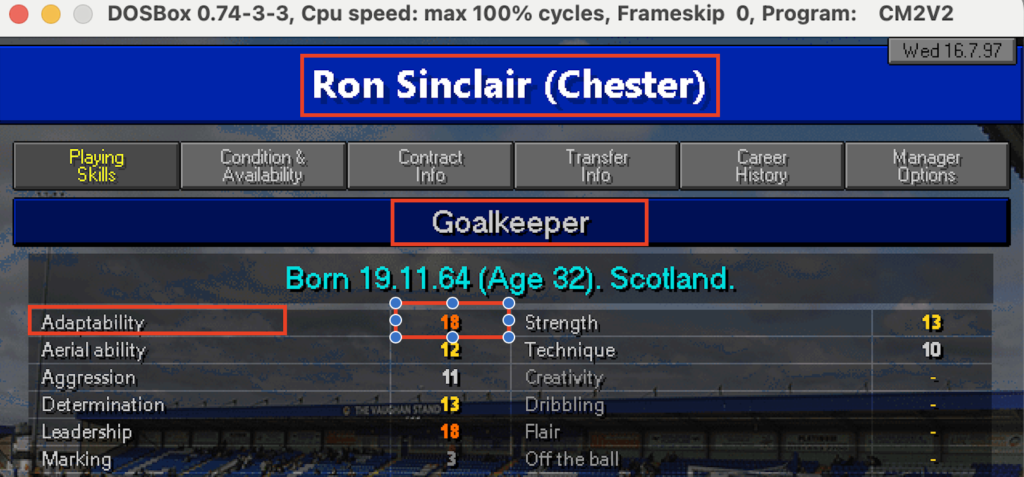
E’ chiaro che sarebbe ideale trovare un modo per estrarre solo le aeree in rosso. Ci sarà? Chiediamo a ChatGPT 🙂

Notare che ho pure scritto wite invece di write, non volontariamente, è solo un typo, ma vediamo come ci risponde.
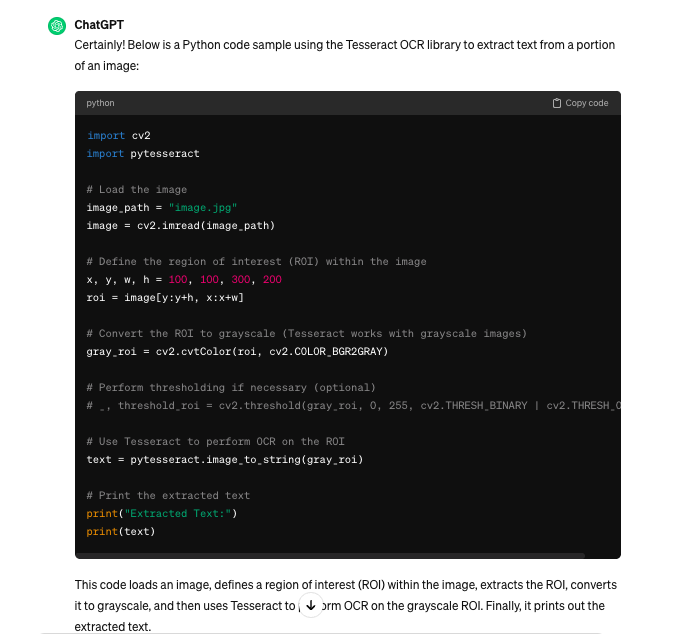
Bene, ChatGPT ci espone tutto il codice da utilizzare: viene definita una ROI (region of interest) dell’immagine, viene convertita in scala di grigio e poi infine si estrae il testo così come facevamo anche nel caso precedente. Ok proviamo con un esempio: proviamo ad estrarre il nome del calciatore:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
print(file)
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
x, y, w, h = 110, 140, 1240, 100
#Define ROI
roi = img[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
plt.imshow(gray_roi, cmap='gray')
plt.show()
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(gray_roi)
# Extract relevant information from the data
print(extracted_data)Come si può notare ho riprodotto fedelmente quanto indicato da ChatGPT, operando qualche accorgimento:
- Itero tutti files presenti nella cartella
- per ognuno di essi fisso x,y,w,h in modo da centrare esattamente il quadro dove sta il nome
- Estraggo il frammento d’immagine con una scala di grigio
- utilizzo una libreria per farmi vedere il frammento e capire se è realmente corretto
- infine faccio scrivere a schermo il testo
Il risultato è questo:

Questo è indubbiamente il risultato che mi serve: qui il testo è stato estratto correttamente e può ora essere utilizzato per qualcosa di più strutturato. Purtroppo la parte più ostica è quella di estrarre delle coordinate corrette in cui trovare il testo che ci serve. Andando per tentativi diventa quasi impossibile, quindi googlando ho scoperto che è possibile attraverso la libreria pyplot visualizzare l’immagine selezionata, di conseguenza andando per tentativi possiamo definire pezzo per pezzo le aeree in cui operare l’estrazione effettiva. A questo punto non ci resta che definire pezzo per pezzo dove prelevare i dati che ci servono, estrarli ed in qualche modo convogliarli in un file di ouput che possa essere utilizzabile per aggregare i dati dei vari giocatori.